
1.1百度蜘蛛抓取建库之Spider抓取系统的基本框架
关于百度以及其它搜索引擎的工作原理,其实大家已经讨论过很多,但随着科技的进步、互联网业的发展,各家搜索引擎都发生着巨大的变化,并且这些变化都是飞快的。我们设计这个章节的目的,除了从官方的角度发出一些声音、纠正一些之前的误读外,还希望通过不断更新内容,与百度搜索引擎发展保持同步,给各位站长带来最新的、与百度高相关的信息。本章主要内容分为四个章节,分别为:抓取建库;检索排序;外部投票;结果展现。
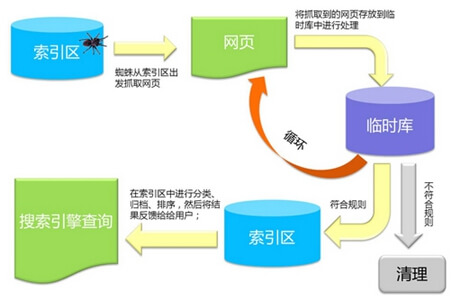

Spider抓取系统的基本框架:
互联网信息爆发式增长,如何有效的获取并利用这些信息是搜索引擎工作中的首要环节。数据抓取系统作为整个搜索系统中的上游,主要负责互联网信息的搜集、保存、更新环节,它像蜘蛛一样在网络间爬来爬去,因此通常会被叫做“spider”。例如我们常用的几家通用搜索引擎蜘蛛被称为:Baiduspdier、Googlebot、Sogou Web Spider等。
Spider抓取系统是搜索引擎数据来源的重要保证,如果把web理解为一个有向图,那么spider的工作过程可以认为是对这个有向图的遍历。从一些重要的种子 URL开始,通过页面上的超链接关系,不断的发现新URL并抓取,尽最大可能抓取到更多的有价值网页。对于类似百度这样的大型spider系统,因为每时 每刻都存在网页被修改、删除或出现新的超链接的可能,因此,还要对spider过去抓取过的页面保持更新,维护一个URL库和页面库。
下图为spider抓取系统的基本框架图,其中包括链接存储系统、链接选取系统、dns解析服务系统、抓取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。Baiduspider即是通过这种系统的通力合作完成对互联网页面的抓取工作。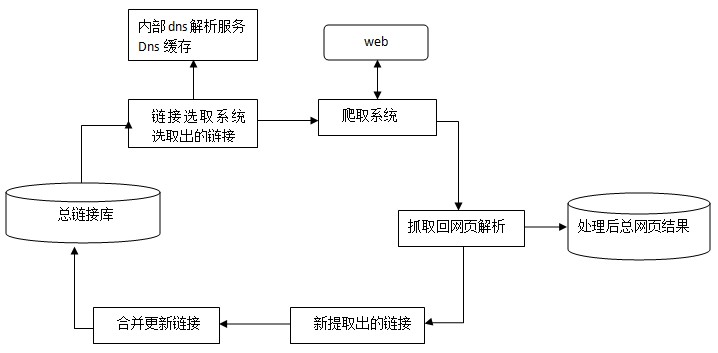
本文转载自百度站长平台,不代表茂名SEO朝勇的博客立场观点,如有侵权请联系删除。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫